掌握排名利器:深入解析'rank函数'的实用技巧与应用
作者:佚名 来源:未知 时间:2024-10-27
在数据分析和处理的日常工作中,排名功能是一项非常重要的技能,它能够帮助我们快速理解数据中的相对位置,从而做出更为精准的决策。在众多数据处理工具中,无论是Excel、SQL数据库查询语言,还是Python的数据处理库(如Pandas),`RANK`函数都是实现排名功能的一个核心工具。本文将详细介绍如何在这些环境中使用`RANK`函数进行排名,以确保即使是对数据分析初学者也能全面理解并掌握这一技能。
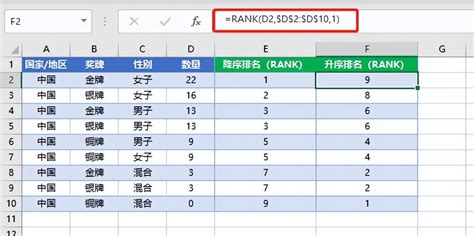
一、Excel中的RANK函数
在Excel中,`RANK`函数是用来确定某一数值在一组数值中的排名,数值的排名是相对于列表中其他数值的大小,如果有两个或更多个相同的数值,则这些数值将获得相同的排名,而下一个数值的排名将跳过相应的位置。
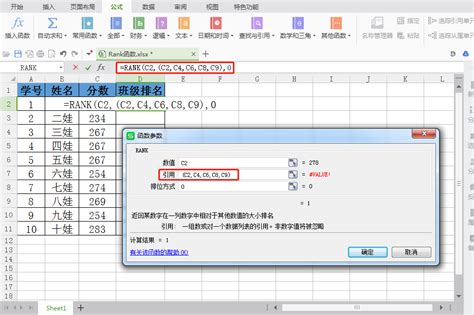
基本语法:
```excel
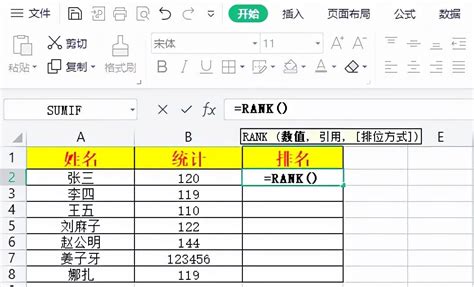
RANK(number, ref, [order])
```
`number`:需要找到排名的那个数值。
`ref`:包含一组数值的数组或区域,`RANK`函数将在此范围内查找`number`的排名。
`[order]`:可选参数,用于指定排名的顺序。0或省略时表示降序(从大到小),非0值(如1)表示升序(从小到大)。
使用示例:
假设我们有一个学生分数的列表在A2:A10,我们想在B列得到每个学生的排名。
1. 在B2单元格输入公式:`=RANK(A2,$A$2:$A$10,0)`。这里,`$A$2:$A$10`是绝对引用,确保拖动填充柄时引用范围不会改变;`0`表示按分数从高到低排名。
2. 将B2单元格的公式向下拖动至B10,以填充其他学生的排名。
二、SQL中的RANK函数
在SQL中,`RANK()`是一个窗口函数(Window Function),用于为结果集中的每一行分配一个唯一的排名,与Excel中的`RANK`函数类似,但如果存在相同值,它们会共享相同的排名,并且之后的排名会跳过相应的位置。
基本语法:
```sql
RANK() OVER (
[PARTITION BY column_name, ...]
ORDER BY column_name [ASC|DESC], ...
```
`PARTITION BY`:可选,用于将结果集划分为多个分区,每个分区内的数据独立进行排名。
`ORDER BY`:必选,指定排名的依据,可以是一个或多个列,并指定升序(ASC)或降序(DESC)。
使用示例:
假设我们有一个名为`students`的表,包含`student_id`、`class_id`和`score`字段,我们想要在每个班级内按照分数从高到低对学生进行排名。
```sql
SELECT
student_id,
class_id,
score,
RANK() OVER (PARTITION BY class_id ORDER BY score DESC) AS rank
FROM
students;
```
这条SQL语句会为每个学生分配一个在其所在班级内的排名,相同分数的学生将获得相同的排名,并且排名会跳过相应位置。
三、Python Pandas中的Rank函数
在Python的Pandas库中,`DataFrame.rank()`方法提供了类似于Excel和SQL中`RANK`函数的功能,允许用户对DataFrame中的一列或多列进行排名。
基本语法:
```python
DataFrame.rank(axis=0, method='average', numeric_only=None, na_option='keep', ascending=True, pct=False)
```
`axis`:默认为0,表示沿着行的方向进行排名;若为1,则沿着列的方向。
`method`:处理并列值的方法。`'average'`(默认值)表示平均排名,`'min'`、`'max'`、`'first'`和`'dense'`等其他选项也会影响排名的计算方式。
`numeric_only`:是否仅对数字类型的数据进行排名,已弃用,推荐使用`DataFrame.select_dtypes()`进行预处理。
`na_option`:如何处理NaN值,`'keep'`(默认值)表示保留NaN值不变,`'top'`或`'bottom'`则分别将NaN值视为最大或最小值。
`ascending`:是否按升序排名,默认为True。
`pct`:是否返回排名比例的分数,而非整数排名。
使用示例:
假设我们有一个Pandas的DataFrame `df`,其中包含学生分数。
```python
import pandas as pd
示例DataFrame
data = {'student_id': [1, 2, 3, 4], 'score': [88, 92, 92, 85]}
df = pd.DataFrame(data)
对分数进行
- 上一篇: 探索'碧空如洗'的绝美意境:天空之镜的纯净解析
- 下一篇: 揭秘:常见的系动词大全,你了解多少?





























