高效掌握rank函数的使用方法
作者:佚名 来源:未知 时间:2024-10-27
在数据处理与分析的广阔领域中,`rank`函数作为一种基础而强大的工具,广泛应用于各类数据排序和排名需求中。无论你是在使用Excel、SQL数据库查询、Python数据分析库(如Pandas)还是其他数据分析软件,掌握`rank`函数的使用方法都是提升数据处理能力的关键。本文将从理解`rank`函数的基本概念出发,深入探讨其在不同维度和场景下的应用,以及注意事项,旨在帮助读者全面掌握这一技能。
一、`rank`函数的基本概念
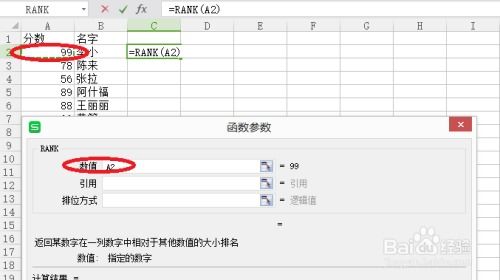
`rank`函数的基本功能是对一组数值进行排序,并为每个数值分配一个排名。与传统排序不同的是,`rank`函数在处理相等值时并不会跳过排名,而是会给予相同的排名,并且会在后续的排名中跳过相应数量的名次,以保持排名的连续性。这种处理方式使得`rank`函数在处理带有并列排名的数据时更加直观和公平。
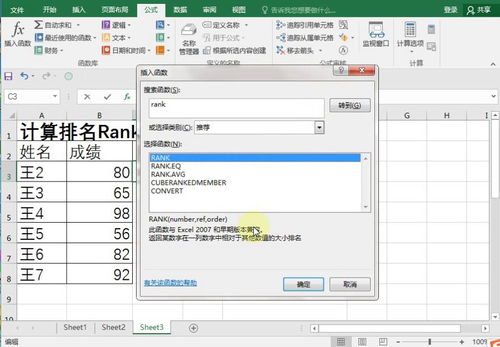
二、Excel中的`RANK`函数
在Excel中,`RANK`函数是最早也是最常见的应用形式之一。其基本语法为:
```excel
RANK(number, ref, [order])
```
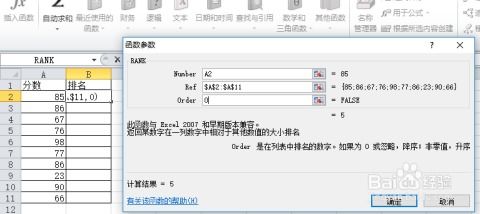
`number`:需要找到排名的那个数值。
`ref`:包含一组数的或对一组数的引用,`RANK`函数会在这组数中给`number`定位排名。
`[order]`:可选参数,用于指定排名方式。0(或省略)表示降序排列,非0值表示升序排列。
应用示例
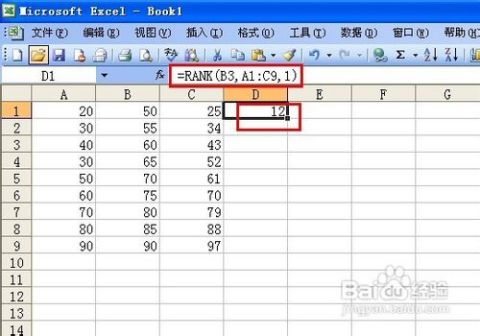
假设我们有一个销售数据列表,希望知道每位销售员的业绩排名。使用`RANK`函数可以轻松地实现这一需求。比如,要找出销售员A的业绩排名,可以使用:
```excel
=RANK(A2,$A$2:$A$10,0)
```
这里假设业绩数据位于A2:A10单元格区域,我们希望按照业绩从高到低进行排名(`order`参数为0或省略)。
三、SQL中的排名函数
虽然SQL没有直接名为`RANK`的函数(严格来说,`RANK()`是SQL中的一个窗口函数),但它提供了几种实现排名的机制,如`RANK()`, `DENSE_RANK()`, 和 `ROW_NUMBER()`等。其中,`RANK()`函数与Excel中的`RANK`函数在功能上最为接近。
`RANK()`窗口函数
SQL中的`RANK()`函数用于对查询结果的某个列进行排名,它可以在使用`OVER()`子句指定的窗口内进行分组排序。其基本语法如下:
```sql
RANK() OVER (
PARTITION BY column_name1, column_name2, ...
ORDER BY column_name3, column_name4, ...
```
`PARTITION BY`:可选,用于将结果集分割成不同的分区,在每个分区内独立进行排名。
`ORDER BY`:指定排名依据的列和排序顺序。
应用示例
假设我们有一个包含销唀数据的表`sales`,字段包括`salesperson_id`(销售员ID)、`year`(年份)和`sales_amount`(销售额)。如果我们想找出每年每个销售员按销售额的排名,可以使用以下SQL语句:
```sql
SELECT
salesperson_id,
year,
sales_amount,
RANK() OVER (PARTITION BY year ORDER BY sales_amount DESC) AS rank
FROM
sales;
```
四、Pandas中的`rank`方法
Pandas作为Python数据分析的强大库,也提供了`rank`方法,用于对数据框(DataFrame)或序列(Series)中的数据进行排名。Pandas的`rank`方法更加灵活,支持多种排名方法(如`'min'`、`'max'`、`'average'`等)以及缺失值处理策略。
使用方法
Pandas的`rank`方法通常作用于DataFrame或Series对象,其基本用法如下:
```python
import pandas as pd
假设df是一个DataFrame
df['ranked_column'] = df['some_column'].rank(method='min', ascending=False, na_option='bottom')
```
`method`:指定排名的计算方式,默认为`'average'`。其他选项包括`'min'`、`'max'`、`'first'`等。
`ascending`:布尔值,指定是否按升序排名。默认为`True`,即升序。
`na_option`:指定如何处理缺失值。常用选项有`'keep'`(保持原始顺序)、`'top'`(视为最大)、`'bottom'`(视为最小)等。
五、注意事项
1. 排名的唯一性:当使用`RANK()`函数时,遇到相同的值时,会给予相同的排名,并在后续排名中





























