如何制作阿里巴巴数据包
作者:佚名 来源:未知 时间:2024-11-15
在制作阿里巴巴数据包的过程中,我们需要了解一系列步骤和技巧,以便高效、准确地抓取网上文章数据,并将其转化为可用的数据包格式。阿里巴巴数据包,通常是以CSV或data结尾的文件,包含了从阿里巴巴平台上导出的宝贝信息,代理商们可以直接导入这些数据包,快速完成宝贝上架,无需再进行逐一编辑。
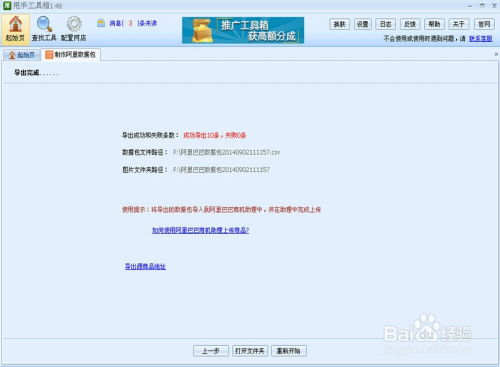
首先,确定我们的目标是抓取阿里巴巴平台上的宝贝信息。这些信息通常包括商品名称、价格、库存、描述、图片等。为了实现这一目标,我们需要选择合适的工具进行数据采集。目前市面上有许多抓取工具可供选择,其中Python爬虫、Octoparse和Parsehub是较为常见的选择。Python爬虫以其高度的自定义性和灵活性著称,适合有一定编程基础的用户;而Octoparse和Parsehub则提供了图形化界面,无需编写代码,更加简单易用。
以Python爬虫为例,首先需要安装好Python环境和相应的爬虫库,如requests、BeautifulSoup等。这些库将帮助我们向目标网站发送请求,并解析返回的网页内容。在开始抓取之前,我们需要准备一份关键词列表,这些关键词应涵盖所有可能涉及的阿里巴巴宝贝信息,如“阿里巴巴数据包制作”、“阿里巴巴商品抓取”等。这些关键词不仅可以帮助我们定位目标网页,还可以用于后续的数据分析和过滤。
在Python爬虫中,我们需要设置爬虫规则,包括爬取的起始页面、爬取深度、爬取频率等。同时,我们还需要设置关键词匹配模式和信息提取规则。这些规则将指导爬虫如何识别并提取网页中的有用信息。例如,我们可以使用正则表达式或BeautifulSoup等工具,从网页的HTML代码中提取出商品名称、价格等关键信息。
在开始正式抓取之前,对爬虫进行测试是非常必要的。测试可以帮助我们发现并解决潜在的问题和错误,确保爬虫能够按预期工作。测试通过后,我们就可以启动爬虫,开始采集网页内容了。在这个过程中,需要注意的是,为了防止被网站屏蔽或封禁,我们需要合理地控制访问频率和间隔时间。过度频繁的访问可能会给网站带来过大负担,甚至触发反爬虫机制。
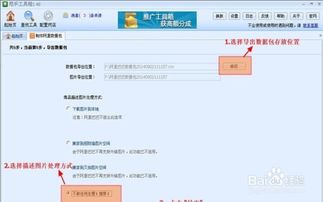
抓取到的数据可能存在一些不规范或重复的情况,因此需要进行数据清洗。数据清洗包括去重、去噪声、数据格式转换等操作。例如,我们可能需要去除网页中的广告信息、无关链接等噪声数据;将价格数据从字符串格式转换为数值格式;对重复的商品信息进行合并等。清洗完毕后,我们需要将数据存储到数据库或文件中。常用的数据库包括MySQL、MongoDB等;常用的文件格式包括CSV、Excel等。
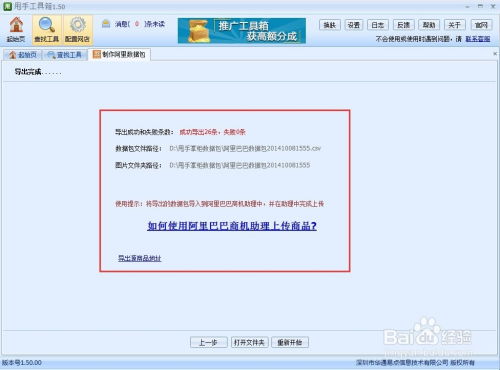
以CSV文件为例,我们可以将清洗后的数据按照特定的格式保存为CSV文件。这个文件就是我们的阿里巴巴数据包。在保存时,需要注意数据的完整性和一致性。例如,确保每个商品都有完整的名称、价格、库存等信息;确保数据之间没有遗漏或重复。此外,还可以对数据包进行进一步的优化和压缩,以便更快地导入到其他平台或进行后续处理。
制作完成的阿里巴巴数据包可以用于多种场景。对于代理商来说,他们可以直接导入数据包到阿里巴巴或其他电商平台的后台,快速完成宝贝上架。这不仅节省了时间和精力,还提高了工作效率和准确性。对于数据分析师来说,他们可以使用数据包进行进一步的数据分析和挖掘。例如,分析不同商品的销量趋势、价格变化等;挖掘潜在的市场机会和竞争态势。
此外,抓取网上文章数据还可以应用于新闻报道、营销推广等领域。在新闻报道中,记者可以通过抓取相关网页的内容,快速获取新闻资讯并用于报道。在营销推广中,营销人员可以通过抓取目标客户的网页浏览记录、购买行为等信息,制定更加精准的营销策略和广告投放计划。
然而,在进行数据抓取时,我们也需要注意一些法律和道德问题。首先,要遵守网络道德规范,不要进行恶意攻击或侵犯他人隐私的行为。其次,要尊重网站所有者的权益,不要过度频繁地访问同一网站或抓取大量数据,以免给网站带来过大负担或损害其商业利益。最后,要注意数据隐私保护,不要将获取到的信息用于非法或商业用途。在合法合规的前提下进行数据抓取和使用,才能确保我们的行为是合法和可持续的。
综上所述,制作阿里巴巴数据包需要一系列步骤和技巧,包括选择合适的抓取工具、准备关键词列表、设置爬虫规则、进行数据清洗和存储等。通过合理规划和操作,我们可以高效地抓取网上文章数据并将其转化为可用的数据包格式。这些数据包不仅可以用于快速上架商品、提高工作效率;还可以用于数据分析、新闻报道、营销推广等多个领域。在数据抓取和使用过程中,我们要始终遵守法律和道德规范,确保我们的行为是合法和可持续的。