掌握robots文件写法与详细说明
作者:佚名 来源:未知 时间:2025-01-28
robots写法和说明
在网络世界中,搜索引擎使用Spider程序自动访问互联网上的网页并获取网页信息。Spider在访问一个网站时,会首先检查该网站的根域下是否有一个叫做robots.txt的纯文本文件。robots.txt文件是网站与搜索引擎Spider之间的一种通信方式,通过该文件,网站可以声明哪些部分不想被搜索引擎访问,或者指定搜索引擎只收录特定的部分。本文将对robots.txt文件的写法和说明进行全面介绍,帮助网站管理员更好地控制搜索引擎对自己网站的抓取行为。

一、robots.txt文件的作用
robots.txt文件的主要作用是告诉搜索引擎Spider哪些页面可以抓取,哪些页面不能抓取。通过合理设置robots.txt文件,可以避免搜索引擎抓取到网站中不希望公开的内容,如后台管理页面、搜索结果页面、重复页面等。同时,robots.txt文件还可以引导搜索引擎Spider优先抓取网站中的重要页面,提高网站的搜索引擎排名和权重。
二、robots.txt文件的放置位置
robots.txt文件应该放置在网站的根目录下,即与网站的index.html或index.php等首页文件在同一目录下。搜索引擎Spider在访问一个网站时,会自动查找该目录下的robots.txt文件,并根据文件内容进行相应的抓取行为。

三、robots.txt文件的写法
robots.txt文件的写法相对简单,主要包括User-agent、Disallow和Allow三个指令。下面将详细介绍这三个指令的用法及示例。
1. User-agent指令
User-agent指令用于指定robots.txt文件适用于哪些搜索引擎Spider。不同的搜索引擎Spider有不同的名称,如谷歌的Googlebot、百度的Baiduspider、微软的MSNbot等。
适用于所有搜索引擎Spider:
```txt
User-agent:
```
这里的星号(*)代表所有的搜索引擎种类。
仅适用于特定搜索引擎Spider:
```txt
User-agent: Googlebot
```
或
```txt
User-agent: Baiduspider
```
2. Disallow指令
Disallow指令用于指定不希望被搜索引擎Spider抓取的页面或目录。
禁止所有搜索引擎Spider抓取所有页面:
```txt
User-agent:
Disallow: /
```
这里的斜杠(/)表示根目录,即禁止抓取网站的所有内容。
禁止特定搜索引擎Spider抓取所有页面:
```txt
User-agent: Baiduspider
Disallow: /
```
即禁止百度的Spider抓取网站的所有内容。
禁止所有搜索引擎Spider抓取特定目录:
```txt
User-agent:
Disallow: /admin/
```
即禁止抓取网站的admin目录及其子目录。
禁止所有搜索引擎Spider抓取特定页面:
```txt
User-agent:
Disallow: /abc.html
```
即禁止抓取网站的abc.html页面。
使用通配符匹配多个页面或目录:
通配符“*”可以匹配0个或多个任意字符,“$”可以匹配URL结尾的字符。
```txt
User-agent:
Disallow: /abc/*.htm
```
即禁止抓取网站abc目录及其子目录下所有以.htm为后缀的页面。
3. Allow指令
Allow指令用于指定允许搜索引擎Spider抓取的页面或目录。需要注意的是,Allow指令通常与Disallow指令结合使用,以明确允许和禁止抓取的页面范围。
允许所有搜索引擎Spider抓取特定目录:
```txt
User-agent:
Allow: /public/
```
即允许抓取网站的public目录及其子目录。
在禁止抓取的基础上允许特定目录:
```txt
User-agent:
Disallow: /
Allow: /public/
```
这里的设置看似矛盾,但实际上,搜索引擎Spider会先读取Disallow指令,再读取Allow指令。因此,这个设置的意思是禁止抓取网站的所有内容,但允许抓取public目录及其子目录。需要注意的是,Allow指令必须放在Disallow指令之前,否则不起作用。
4. Sitemap指令(可选)
Sitemap指令用于指定网站的站点地图(Sitemap)文件的位置。站点地图是一个包含网站上所有页面链接的XML文件,有助于搜索引擎Spider更快地发现和抓取网站的内容。
```txt
User-agent:
Sitemap: http://www.example.com/sitemap.xml
```
即指定网站的站点地图文件位于http://www.example.com/sitemap.xml。
四、robots.txt文件的示例
以下是一个robots.txt文件的示例,展示了如何结合使用User-agent、Disallow和Allow指令来控制搜索引擎Spider的抓取行为。
```txt
User-agent:
Disallow: /admin/
Disallow: /search/
Disallow: /tmp/
Allow: /public/
User-agent: Baiduspider
Disallow: /images/
User-agent: Googlebot
Allow: /blog/
Disallow: /blog/private/
Sitemap: http://www.example.com/sitemap.xml
```
这个示例中:
所有搜索引擎Spider都被禁止抓取/admin/、/search/和/tmp/目录。
所有搜索引擎Spider都被允许抓取/public/目录。
百度的Spider被禁止抓取/images/目录。
谷歌的Spider被允许抓取/blog/目录,但禁止抓取/blog/private/目录。
网站的站点地图文件位于http://www.example.com/sitemap.xml。
五、注意事项
1. 规范性:在编写robots.txt文件时,务必遵循其语法规范,确保指令的正确性和有效性。
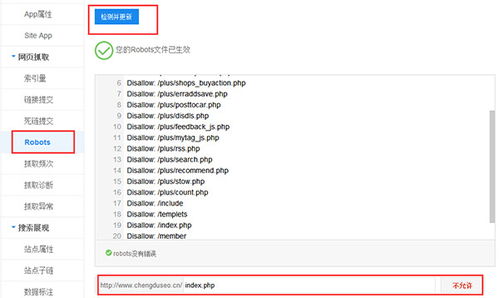
2. 测试与验证:在将robots.txt文件上传到网站后,应使用搜索引擎的robots.txt测试工具进行测试和验证,以确保其正确解析和生效。
3. 定期更新:随着网站内容的更新和变化,robots.txt文件也应相应地进行调整和优化,以确保其始终符合网站的需求和搜索引擎的抓取规则。
通过合理设置robots.txt文件,网站管理员可以更好地控制搜索引擎对自己网站的抓取行为,提高网站的搜索引擎排名和权重。同时,也有助于保护网站的安全和隐私,避免搜索引擎抓取到不希望公开的内容。
- 上一篇: 制作毛血旺的详细步骤
- 下一篇: 如何获取神仙道境界点




























